How to perform when it comes to performance
This was originally written for Administrate's engineering blog.
As an engineer early in my career, I haven't had a lot of experience with optimising systems for performance. Most of my work has been focused on individual user stories or journeys. In these cases, the consideration of performance has largely been scoped to pieces of code - is a function efficient? Is a React component rendering too often?
That's not to say that I haven't cared about the overall performance or the experience of the end user, but I had been prioritising code that worked and was readable. I would describe it as being pragmatic about performance. You can always be chasing better performance, but it's important to know when that will deliver value and when it won't.
This blog post is about how my recent experience of focusing on performance has changed how I’ll work for the rest of my career.
Background #
I recently had the opportunity to work on a project where our entire focus was improving the performance of Administrate’s e-commerce API. This GraphQL API is highly utilised and serves a catalogue of training that our customers sell to their customers, so it's important that it's quick to search and filter in order to enhance discoverability.
However, the performance degraded as more functionality was added to this API. At the start of the project, the P90 (90th percentile) response time of the catalogue was 4.2 seconds. In some rare cases, response times were as slow as 36 seconds! Good job that transparency is one of our values at Administrate, otherwise I probably wouldn't be sharing these numbers.
There are many opinions on what an "acceptable" load time is for users, but the consensus tends to be somewhere around 2 seconds or less. With this in mind, we set ourselves the ambitious target of a P90 response time of less than 1 second.
Three weeks and multiple PRs later, we were seeing a P90 response time of 1.5 seconds for the catalogue! The slowest response time is now 3.5 seconds, meaning we achieved a 64% reduction in the P90 response time of the catalogue. The chart below shows the P90 response time over the course of the project:
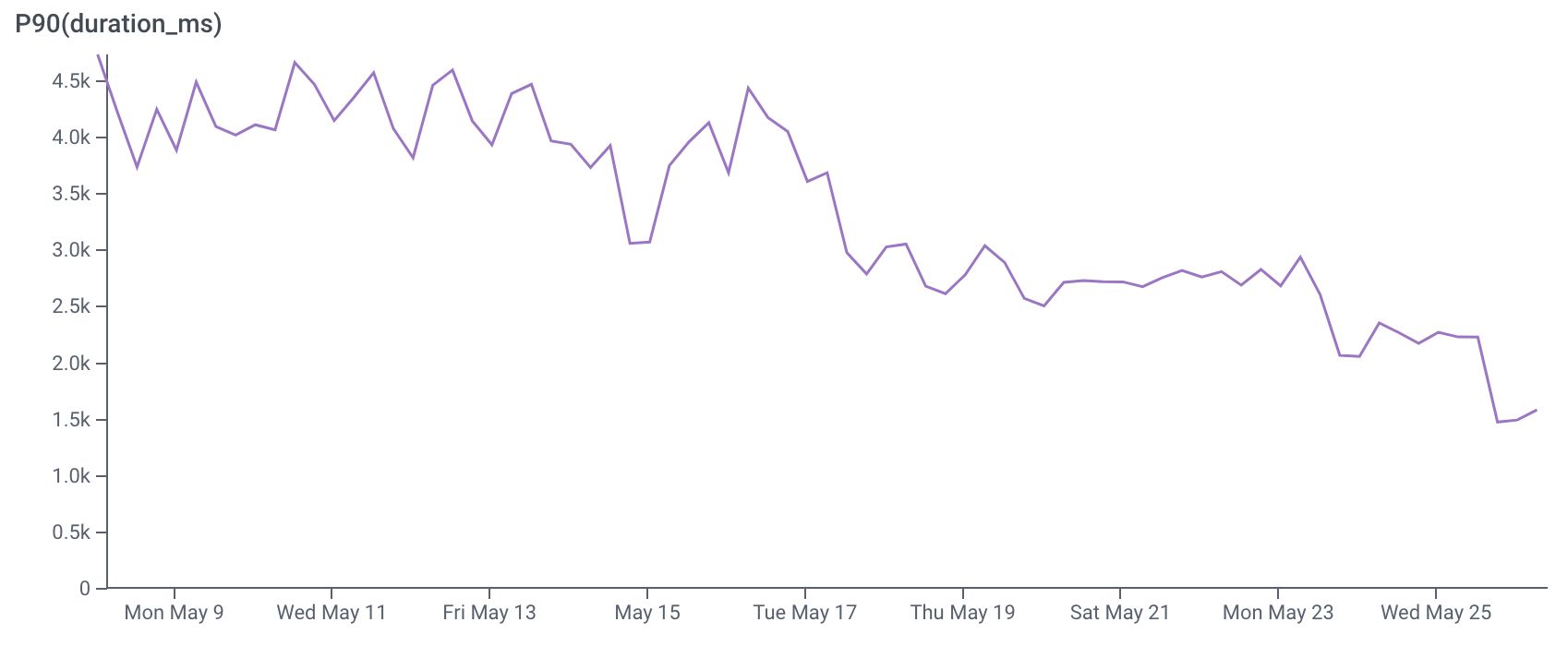
I could write another whole blog post with the technical details of how we managed to achieve this, but a lot of it was specific to our architecture and tech stack at Administrate. Instead, I'm going to share the key lessons that I learned over the course of the project.
Monitor your success #
At Administrate, we always decide how to measure the success of a project in the earliest stages of solutioning. So we knew from the start of the project that a P90 response time of less than 1 second for the catalogue was our goal. However, despite this clear success criterion from the start, we made the mistake of adding monitoring for the response time at the end of the project. Our reasoning was we wanted to add a metric alarm in CloudWatch that would alert us if the response time went above our defined threshold, preventing it from just slowly creeping up again. If we were to tackle this sort of project again, we would add the monitoring of the metric at the start.
Observability isn't just a buzzword #
‘Observability’ is a hot software engineering buzzword, and is essentially a way of saying that you know what’s going on in your system. There are several different tools (both open source and from vendors) that offer a view into data that you have captured in your system in order to provide observability and provide ways for you to collect, store and visualise telemetry data such as traces, metrics and logs.
At Administrate, we use Honeycomb. Luckily, we've been using Honeycomb and collecting telemetry data for a while, so we had plenty to pour over when it came to the performance of the catalogue. Using this data, we identified slow requests (traces) and could see which parts (spans) were the most problematic. Slicing the data based on the shape of the GraphQL request or the customer helped us to identify what sort of data and conditions were causing the bottlenecks.
An example of a trace, with underlying spans, is shown below:
a
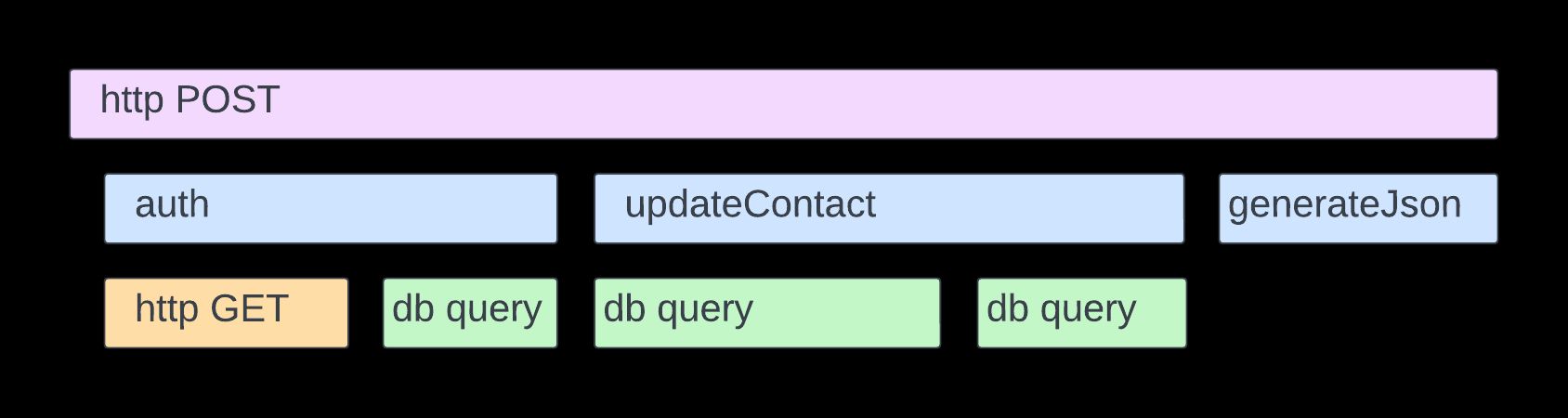
Honeycomb’s insight was invaluable. When testing our changes, we enabled telemetry in our development environments and this allowed us to easily identify whether we had improved performance or not.
Personally, I found it very enlightening to see exactly what the system was doing and how each span performed. Honeycomb allowed me to peek behind the curtain of my code to see exactly what it did rather than just assuming it was doing what I thought it would.
I will definitely use Honeycomb more in the future. Not just after shipping a change, but also during development to give me greater insight into the code I'm writing.
Performance is simple #
Looking at the changes we made during this project, none of them were particularly complex. Most of them boiled down to some combination of:
- Fetching less data so that we only retrieved the bare minimum we needed
- Reducing the number of database queries we made
- Simplifying the business logic
It's worth noting that we had to do a number of the above to get the performance to an acceptable level. There was no one silver bullet. This reminded me of the importance of considering the code I write. That doesn't have to mean agonising over every line or optimising every function, but keeping the overall context in mind and considering if there is a simpler approach. However, it's important to not just write performant code for the sake of it. You should do it because you understand how it fits into the performance of the wider system and how it will impact users.
If someone had asked me before this project how much effort would be required to improve the API performance, I would have assumed a lot more. I would have expected large architectural refactoring and changing the way we store the data or the introduction of caching at least. However, by using just some observability tools and fundamental software engineering techniques, we delivered a hugely noticeable improvement for our customers, which means we can be #ProudOfOurWork!
- Previous: Learning to cope with Internet Explorer 11
- Next: Walking the Dava Way